Лента новостей → Может ли ChatGPT поддерживать решения по диагностической визуализации?
Исследование, подтверждающее концепцию, предполагает, что ChatGPT-4 может генерировать соответствующие дифференциальные диагнозы для определенных моделей изображений, сообщила исследовательская группа из Кельнского университета в Германии.
Исследователи под руководством доктора Джонатана Коттлорса проверили возможности большой языковой модели (LLM) по сравнению с группой экспертов по четырем специальностям радиологии и обнаружили высокие показатели соответствия. Исследование подчеркивает потенциал ChatGPT для поддержки диагностических решений, пишет группа.
«Одним из важных преимуществ предлагаемого подхода является потенциально значительная экономия времени по сравнению с традиционным литературным исследованием, что может быть особенно важно для рентгенологов, проходящих обучение с целью совместить клиническую эффективность и постоянное расширение знаний», — написали исследователи в статье, опубликованной 5 июля. в радиологии .
Распознавание паттернов изображений и их соотнесение с определенными патологиями являются ключевыми этапами диагностического процесса в радиологии, и врачи часто обращаются к соответствующей литературе для подтверждения или уточнения диагнозов. LLM, такие как ChatGPT-4 от OpenAI, позволяют получать доступ и контекстуализировать огромные объемы информации.
В этом исследовании группа выдвинула гипотезу о том, что использование способности ChatGPT-4 понимать и генерировать текстовую информацию, подобную человеческой, можно использовать для имитации процесса получения важных дифференциальных диагнозов для определенных моделей изображений.
Исследователи выбрали четыре модели изображений с потенциальными дифференциальными диагнозами в нейрорадиологии, абдоминальной и скелетно-мышечной радиологии. Затем они ввели текстовые описания паттернов в GPT-4 и предложили ему предоставить пять наиболее важных дифференциальных диагнозов.
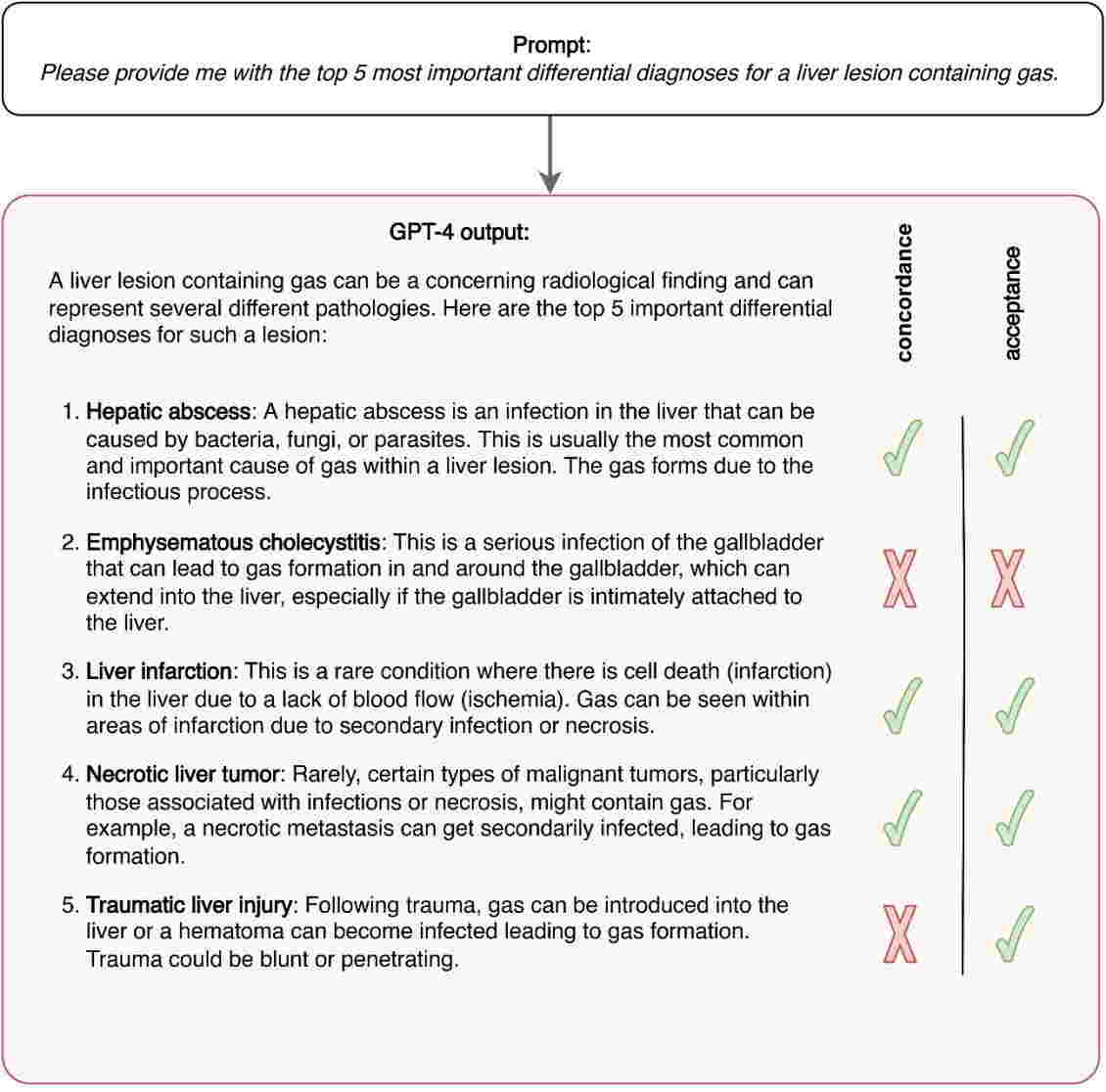
Затем три эксперта в каждой области представили свое мнение о пяти наиболее важных дифференциальных диагнозах для каждой модели. Экспертов также попросили определить количество «приемлемых» диагнозов ИИ.
Согласно анализу, GPT-4 достиг соответствия 68,8% (55 из 80) с экспертами при определении основных дифференциальных диагнозов на основе изображений, и 93,8% (75 из 80) дифференциальных диагнозов, предложенных GPT-4, были признаны приемлемые альтернативы.
«Наше исследование служит доказательством концепции способности LLM генерировать соответствующие дифференциальные диагнозы для определенных шаблонов визуализации и, следовательно, их потенциала для поддержки диагностических решений», — пишут исследователи.
Они отметили, что необходимы дальнейшие исследования.
«Наши результаты являются предварительными и подвержены предвзятости из-за ретроспективного дизайна исследования, требующего проверки в проспективных реальных условиях, подразумевающей контекстуализацию и интеграцию клинической информации, не связанной с визуализацией», — заключили исследователи.
Источник