Лента новостей → В специальном отчете излагаются передовые методы работы с предвзятостью в радиологии ИИ
Согласно специальному отчету, опубликованному в журнале « Радиология: искусственный интеллект », с ростом использования ИИ в радиологии крайне важно свести к минимуму предвзятость в системах машинного обучения, прежде чем внедрять их в реальные клинические сценарии .
В отчете, первом в серии из трех частей, описываются неоптимальные методы, используемые на этапе обработки данных при разработке системы машинного обучения, и представлены стратегии по их устранению.
«Существует 12 неоптимальных практик, которые происходят на этапе обработки данных при разработке системы машинного обучения, каждая из которых может предрасполагать систему к систематической ошибке», — сказал Брэдли Дж. Эриксон, доктор медицинских наук, профессор радиологии и директор Центра. Лаборатория искусственного интеллекта в клинике Майо в Рочестере, штат Миннесота. «Если эти систематические предубеждения не распознаются или не поддаются точной количественной оценке, это приведет к субоптимальным результатам, что ограничит применение ИИ реальными сценариями».
Доктор Эриксон сказал, что тема надлежащей обработки данных привлекает все больше внимания, однако руководств по правильному управлению большими данными мало.
«Регуляторные проблемы и пробелы в переводе по-прежнему препятствуют внедрению машинного обучения в реальных клинических сценариях. Однако мы ожидаем, что экспоненциальный рост систем искусственного интеллекта для радиологии ускорит устранение этих барьеров», — сказал д-р Эриксон. «Чтобы подготовить системы машинного обучения к внедрению и клиническому внедрению, очень важно свести к минимуму предвзятость».
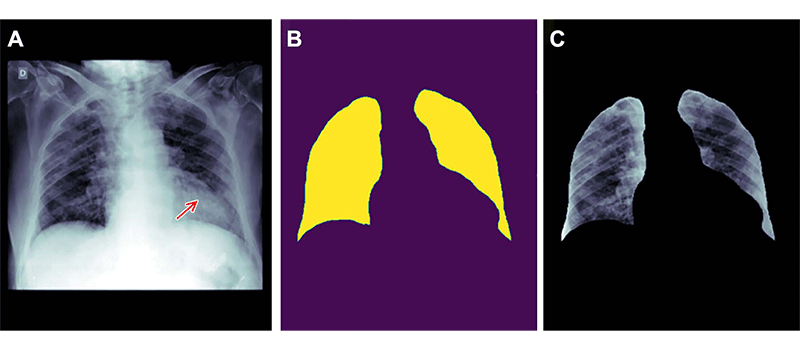
Пример того, как неправильное удаление признаков из данных изображения может привести к систематической ошибке. (A) Рентгенограмма грудной клетки пациента мужского пола с пневмонией. (B) Маска сегментации легкого, созданная с использованием модели глубокого обучения. (C) Рентгенограмма грудной клетки обрезана на основе маски сегментации. Если кадрированную рентгенограмму грудной клетки отправить в следующий классификатор для обнаружения уплотнений, то уплотнение, расположенное за сердцем, будет пропущено (стрелка, A ). Это происходит из-за того, что удаление первичного признака с использованием модели сегментации было недействительным и без необходимости удаляло часть легкого, расположенную позади сердца.
Стратегии помогают бороться с неоптимальными практиками
В отчете д-р Эриксон и его команда предлагают стратегии смягчения последствий для 12 неоптимальных практик, возникающих на четырех этапах обработки данных при разработке системы машинного обучения (по три на каждый этап обработки данных), в том числе:
- Сбор данных — неправильная идентификация набора данных, единственный источник данных, ненадежный источник данных.
- Исследование данных – неадекватный исследовательский анализ данных, исследовательский анализ данных без знания предметной области, неспособность наблюдать за фактическими данными.
- Разделение данных — утечка между наборами данных, нерепрезентативные наборы данных, подгонка под гиперпараметры.
- Инжиниринг данных – неправильное удаление функций, неправильное масштабирование функций, неправильное управление отсутствующими данными.
Доктор Эриксон сказал, что медицинские данные часто далеки от идеального использования в качестве входных данных для алгоритмов машинного обучения.
«Каждый из этих шагов может быть подвержен систематической или случайной предвзятости», — сказал он. «Разработчики несут ответственность за точную обработку данных в сложных сценариях, таких как выборка данных, деидентификация, аннотация, маркировка и управление отсутствующими значениями».
Согласно отчету, тщательное планирование перед сбором данных должно включать углубленный обзор клинической и технической литературы и сотрудничество с экспертами в области обработки данных.
«В междисциплинарных командах по машинному обучению должны быть члены или лидеры, обладающие как наукой о данных, так и предметной (клинической) экспертизой», — сказал он.
Чтобы разработать более разнородный набор обучающих данных, д-р Эриксон и его соавторы предлагают собирать данные из нескольких учреждений из разных географических мест, использовать данные от разных поставщиков и за разное время или включать общедоступные наборы данных.
«Создание надежной системы машинного обучения требует от исследователей детективной работы и поиска способов, которыми данные могут вас обмануть», — сказал он. «Прежде чем вы поместите данные в учебный модуль, вы должны проанализировать их, чтобы убедиться, что они отражают вашу целевую группу. ИИ не сделает это за вас».
Доктор Эриксон сказал, что даже после отличной обработки данных системы машинного обучения все еще могут быть подвержены значительным ошибкам. Второй и третий отчеты из серии « Радиология: искусственный интеллект » посвящены систематическим ошибкам, возникающим на этапах разработки модели, ее оценки и отчетности.
«В последние годы машинное обучение продемонстрировало свою полезность во многих областях клинических исследований, от реконструкции изображений и проверки гипотез до улучшения инструментов диагностики, прогнозирования и мониторинга», — сказал доктор Эриксон. «Эта серия отчетов направлена на выявление ошибочных практик во время разработки машинного обучения и устранение как можно большего их количества».
Чтобы получить больше информации
Прочтите отчет « Радиология: искусственный интеллект » «Снижение предвзятости в машинном обучении радиологии: 1. Обработка данных».